
sqlиҜӯжі•зҡ„еҲҶжһҗжҳҜд»ҺеҸіеҲ°е·Ұ
В
дёҖгҖҒsqlиҜӯеҸҘзҡ„жү§иЎҢжӯҘйӘӨпјҡ
1пјүиҜӯжі•еҲҶжһҗпјҢеҲҶжһҗиҜӯеҸҘзҡ„иҜӯжі•жҳҜеҗҰз¬ҰеҗҲ规иҢғпјҢиЎЎйҮҸиҜӯеҸҘдёӯеҗ„иЎЁиҫҫејҸзҡ„ж„Ҹд№үгҖӮ
2пјүиҜӯд№үеҲҶжһҗпјҢжЈҖжҹҘиҜӯеҸҘдёӯж¶үеҸҠзҡ„жүҖжңүж•°жҚ®еә“еҜ№иұЎжҳҜеҗҰеӯҳеңЁпјҢдё”з”ЁжҲ·жңүзӣёеә”зҡ„жқғйҷҗгҖӮ
3пјүи§ҶеӣҫиҪ¬жҚўпјҢе°Ҷж¶үеҸҠи§Ҷеӣҫзҡ„жҹҘиҜўиҜӯеҸҘиҪ¬жҚўдёәзӣёеә”зҡ„еҜ№еҹәиЎЁжҹҘиҜўиҜӯеҸҘгҖӮ
4пјүиЎЁиҫҫејҸиҪ¬жҚўпјҢ е°ҶеӨҚжқӮзҡ„ SQL иЎЁиҫҫејҸиҪ¬жҚўдёәиҫғз®ҖеҚ•зҡ„зӯүж•ҲиҝһжҺҘиЎЁиҫҫејҸгҖӮ
5пјүйҖүжӢ©дјҳеҢ–еҷЁпјҢдёҚеҗҢзҡ„дјҳеҢ–еҷЁдёҖиҲ¬дә§з”ҹдёҚеҗҢзҡ„вҖңжү§иЎҢи®ЎеҲ’вҖқ
6пјүйҖүжӢ©иҝһжҺҘж–№ејҸпјҢ ORACLE жңүдёүз§ҚиҝһжҺҘж–№ејҸпјҢеҜ№еӨҡиЎЁиҝһжҺҘ ORACLE еҸҜйҖүжӢ©йҖӮеҪ“зҡ„иҝһжҺҘж–№ејҸгҖӮ
7пјүйҖүжӢ©иҝһжҺҘйЎәеәҸпјҢ еҜ№еӨҡиЎЁиҝһжҺҘ ORACLE йҖүжӢ©е“ӘдёҖеҜ№иЎЁе…ҲиҝһжҺҘпјҢйҖүжӢ©иҝҷдёӨиЎЁдёӯе“ӘдёӘиЎЁеҒҡдёәжәҗж•°жҚ®иЎЁгҖӮ
8пјүйҖүжӢ©ж•°жҚ®зҡ„жҗңзҙўи·Ҝеҫ„пјҢж №жҚ®д»ҘдёҠжқЎд»¶йҖүжӢ©еҗҲйҖӮзҡ„ж•°жҚ®жҗңзҙўи·Ҝеҫ„пјҢеҰӮжҳҜйҖүз”Ёе…ЁиЎЁжҗңзҙўиҝҳжҳҜеҲ©з”Ёзҙўеј•жҲ–жҳҜе…¶д»–зҡ„ж–№ејҸгҖӮ
9пјүиҝҗиЎҢвҖңжү§иЎҢи®ЎеҲ’вҖқ
В
В
дәҢгҖҒoracle е…ұдә«еҺҹзҗҶпјҡ
В В В ORACLEе°Ҷжү§иЎҢиҝҮзҡ„SQLиҜӯеҸҘеӯҳж”ҫеңЁеҶ…еӯҳзҡ„е…ұдә«жұ (shared buffer pool)дёӯпјҢеҸҜд»Ҙиў«жүҖжңүзҡ„ж•°жҚ®еә“з”ЁжҲ·е…ұдә«гҖӮ
еҪ“дҪ жү§иЎҢдёҖдёӘSQLиҜӯеҸҘ(жңүж—¶иў«з§°дёәдёҖдёӘжёёж Ү)ж—¶пјҢеҰӮжһңе®ғе’Ңд№ӢеүҚзҡ„жү§иЎҢиҝҮзҡ„иҜӯеҸҘе®Ңе…ЁзӣёеҗҢпјҢORACLEе°ұиғҪеҫҲеҝ«иҺ·еҫ—е·Із»Ҹиў«и§Јжһҗзҡ„иҜӯеҸҘд»ҘеҸҠжңҖеҘҪзҡ„жү§иЎҢи·Ҝеҫ„.гҖӮиҝҷдёӘеҠҹиғҪеӨ§еӨ§ең°жҸҗй«ҳдәҶSQLзҡ„жү§иЎҢжҖ§иғҪ并иҠӮзңҒдәҶеҶ…еӯҳзҡ„дҪҝз”ЁгҖӮ
В
дёүгҖҒoracle иҜӯеҸҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮзҡ„ж–№жі•пјҡ
1пјҡwhere column in(select * from ... where ...);
2пјҡ... where exists (select 'X' from ...where ...);
В
第дәҢз§Қж јејҸиҰҒиҝңжҜ”第дёҖз§Қж јејҸзҡ„ж•ҲзҺҮй«ҳгҖӮ
В
еңЁOracleдёӯеҸҜд»ҘеҮ д№Һе°ҶжүҖжңүзҡ„INж“ҚдҪңз¬ҰеӯҗжҹҘиҜўж”№еҶҷдёәдҪҝз”ЁEXISTSзҡ„еӯҗжҹҘиҜўгҖӮ
дҪҝз”ЁEXISTпјҢOracleзі»з»ҹдјҡйҰ–е…ҲжЈҖжҹҘдё»жҹҘиҜўпјҢ然еҗҺиҝҗиЎҢеӯҗжҹҘиҜўзӣҙеҲ°е®ғжүҫеҲ°з¬¬дёҖдёӘеҢ№й…ҚйЎ№пјҢ
иҝҷе°ұиҠӮзңҒдәҶж—¶й—ҙOracleзі»з»ҹеңЁжү§иЎҢINеӯҗжҹҘиҜўж—¶пјҢйҰ–е…Ҳжү§иЎҢеӯҗжҹҘиҜўпјҢ并е°ҶиҺ·еҫ—зҡ„з»“жһңеҲ—иЎЁеӯҳж”ҫеңЁеңЁдёҖдёӘеҠ дәҶзҙўеј•зҡ„дёҙж—¶иЎЁдёӯгҖӮ
В
йҒҝе…ҚдҪҝз”ЁhavingеӯҗеҸҘгҖӮHAVING еҸӘдјҡеңЁжЈҖзҙўеҮәжүҖжңүи®°еҪ•д№ӢеҗҺжүҚеҜ№з»“жһңйӣҶиҝӣиЎҢиҝҮж»ӨгҖӮ
иҝҷдёӘеӨ„зҗҶйңҖиҰҒжҺ’еәҸпјҢжҖ»и®Ўзӯүж“ҚдҪңгҖӮеҰӮжһңиғҪйҖҡиҝҮWHEREеӯҗеҸҘйҷҗеҲ¶и®°еҪ•зҡ„ж•°зӣ®пјҢйӮЈе°ұиғҪеҮҸе°‘иҝҷж–№йқўзҡ„ејҖй”ҖгҖӮ
В
еӣӣгҖҒSQL SelectиҜӯеҸҘе®Ңж•ҙзҡ„жү§иЎҢйЎәеәҸпјҡВ
1гҖҒfromеӯҗеҸҘз»„иЈ…жқҘиҮӘдёҚеҗҢж•°жҚ®жәҗзҡ„ж•°жҚ®пјӣ
2гҖҒwhereеӯҗеҸҘеҹәдәҺжҢҮе®ҡзҡ„жқЎд»¶еҜ№и®°еҪ•иЎҢиҝӣиЎҢзӯӣйҖүпјӣ
3гҖҒgroup byеӯҗеҸҘе°Ҷж•°жҚ®еҲ’еҲҶдёәеӨҡдёӘеҲҶз»„пјӣ
4гҖҒдҪҝз”ЁиҒҡйӣҶеҮҪж•°иҝӣиЎҢи®Ўз®—пјӣ
5гҖҒдҪҝз”ЁhavingеӯҗеҸҘзӯӣйҖүеҲҶз»„пјӣ
6гҖҒи®Ўз®—жүҖжңүзҡ„иЎЁиҫҫејҸпјӣ
7гҖҒselect зҡ„еӯ—ж®өпјӣ
8гҖҒдҪҝз”Ёorder byеҜ№з»“жһңйӣҶиҝӣиЎҢжҺ’еәҸгҖӮ
SQLиҜӯиЁҖдёҚеҗҢдәҺе…¶д»–зј–зЁӢиҜӯиЁҖзҡ„жңҖжҳҺжҳҫзү№еҫҒжҳҜеӨ„зҗҶд»Јз Ғзҡ„йЎәеәҸгҖӮеңЁеӨ§еӨҡж•°жҚ®еә“иҜӯиЁҖдёӯпјҢд»Јз ҒжҢүзј–з ҒйЎәеәҸиў«еӨ„зҗҶгҖӮдҪҶеңЁSQLиҜӯеҸҘдёӯпјҢ第дёҖдёӘиў«еӨ„зҗҶзҡ„еӯҗеҸҘејҸFROMпјҢиҖҢдёҚжҳҜ第дёҖеҮәзҺ°зҡ„SELECTгҖӮSQLжҹҘиҜўеӨ„зҗҶзҡ„жӯҘйӘӨеәҸеҸ·пјҡ
В
1 В (8)SELECT В (9) DISTINCT (11) <TOP_specification> <select_list>В
2 В (1) В FROM <left_table> В
3 В (3) <join_type> JOIN <right_table>В
4 В (2) ON <join_condition>В
5 В (4) WHERE <where_condition>В
6 В (5) GROUP BY <group_by_list>В
7 В (6) WITH {CUBE | ROLLUP}В
8 В (7) HAVING <having_condition>В
9 (10) ORDER BY <order_by_list>
гҖҖгҖҖ
д»ҘдёҠжҜҸдёӘжӯҘйӘӨйғҪдјҡдә§з”ҹдёҖдёӘиҷҡжӢҹиЎЁпјҢиҜҘиҷҡжӢҹиЎЁиў«з”ЁдҪңдёӢдёҖдёӘжӯҘйӘӨзҡ„иҫ“е…ҘгҖӮиҝҷдәӣиҷҡжӢҹиЎЁеҜ№и°ғз”ЁиҖ…(е®ўжҲ·з«Ҝеә”з”ЁзЁӢеәҸжҲ–иҖ…еӨ–йғЁжҹҘиҜў)дёҚеҸҜз”ЁгҖӮеҸӘжңүжңҖеҗҺдёҖжӯҘз”ҹжҲҗзҡ„иЎЁжүҚдјҡдјҡз»ҷи°ғз”ЁиҖ…гҖӮеҰӮжһңжІЎжңүеңЁжҹҘиҜўдёӯжҢҮе®ҡжҹҗдёҖдёӘеӯҗеҸҘпјҢе°Ҷи·іиҝҮзӣёеә”зҡ„жӯҘйӘӨгҖӮ
йҖ»иҫ‘жҹҘиҜўеӨ„зҗҶйҳ¶ж®өз®Җд»Ӣпјҡ
1гҖҒ FROMпјҡеҜ№FROMеӯҗеҸҘдёӯзҡ„еүҚдёӨдёӘиЎЁжү§иЎҢз¬ӣеҚЎе°”з§Ҝ(дәӨеҸүиҒ”жҺҘ)пјҢз”ҹжҲҗиҷҡжӢҹиЎЁVT1гҖӮ
2гҖҒ ONпјҡеҜ№VT1еә”з”ЁONзӯӣйҖүеҷЁпјҢеҸӘжңүйӮЈдәӣдҪҝдёәзңҹжүҚиў«жҸ’е…ҘеҲ°TV2гҖӮ
3гҖҒ OUTER (JOIN):еҰӮжһңжҢҮе®ҡдәҶOUTER JOIN(зӣёеҜ№дәҺCROSS JOINжҲ–INNER JOIN)пјҢдҝқз•ҷиЎЁдёӯжңӘжүҫеҲ°еҢ№й…Қзҡ„иЎҢе°ҶдҪңдёәеӨ–йғЁиЎҢж·»еҠ еҲ°VT2пјҢз”ҹжҲҗTV3гҖӮеҰӮжһңFROMеӯҗеҸҘеҢ…еҗ«дёӨдёӘд»ҘдёҠзҡ„иЎЁпјҢеҲҷеҜ№дёҠдёҖдёӘиҒ”жҺҘз”ҹжҲҗзҡ„з»“жһңиЎЁе’ҢдёӢдёҖдёӘиЎЁйҮҚеӨҚжү§иЎҢжӯҘйӘӨ1еҲ°жӯҘйӘӨ3пјҢзӣҙеҲ°еӨ„зҗҶе®ҢжүҖжңүзҡ„иЎЁдҪҚзҪ®гҖӮ
4гҖҒ WHEREпјҡеҜ№TV3еә”з”ЁWHEREзӯӣйҖүеҷЁпјҢеҸӘжңүдҪҝдёәtrueзҡ„иЎҢжүҚжҸ’е…ҘTV4гҖӮ
5гҖҒ GROUP BYпјҡжҢүGROUP BYеӯҗеҸҘдёӯзҡ„еҲ—еҲ—иЎЁеҜ№TV4дёӯзҡ„иЎҢиҝӣиЎҢеҲҶз»„пјҢз”ҹжҲҗTV5гҖӮ
6гҖҒ CUTE|ROLLUPпјҡжҠҠи¶…з»„жҸ’е…ҘVT5пјҢз”ҹжҲҗVT6гҖӮ
7гҖҒ HAVINGпјҡеҜ№VT6еә”з”ЁHAVINGзӯӣйҖүеҷЁпјҢеҸӘжңүдҪҝдёәtrueзҡ„з»„жҸ’е…ҘеҲ°VT7гҖӮ
8гҖҒ SELECTпјҡеӨ„зҗҶSELECTеҲ—иЎЁпјҢдә§з”ҹVT8гҖӮ
9гҖҒ DISTINCTпјҡе°ҶйҮҚеӨҚзҡ„иЎҢд»ҺVT8дёӯеҲ йҷӨпјҢдә§е“ҒVT9гҖӮ
10гҖҒORDER BYпјҡе°ҶVT9дёӯзҡ„иЎҢжҢүORDER BYеӯҗеҸҘдёӯзҡ„еҲ—еҲ—иЎЁйЎәеәҸпјҢз”ҹжҲҗдёҖдёӘжёёж Ү(VC10)гҖӮ
11гҖҒTOPпјҡд»ҺVC10зҡ„ејҖе§ӢеӨ„йҖүжӢ©жҢҮе®ҡж•°йҮҸжҲ–жҜ”дҫӢзҡ„иЎҢпјҢз”ҹжҲҗиЎЁTV11пјҢ并иҝ”еӣһз»ҷи°ғз”ЁиҖ…гҖӮ
В
OracleдёӯSQLиҜӯеҸҘжү§иЎҢиҝҮзЁӢдёӯ,OracleеҶ…йғЁи§ЈжһҗеҺҹзҗҶеҰӮдёӢ:
гҖҖгҖҖ1гҖҒеҪ“дёҖз”ЁжҲ·з¬¬дёҖж¬ЎжҸҗдәӨдёҖдёӘSQLиЎЁиҫҫејҸж—¶,Oracleдјҡе°ҶиҝҷSQLиҝӣиЎҢHard parse,иҝҷиҝҮзЁӢжңүзӮ№еғҸзЁӢеәҸзј–иҜ‘,жЈҖжҹҘиҜӯжі•гҖҒиЎЁеҗҚгҖҒеӯ—ж®өеҗҚзӯүзӣёе…ідҝЎжҒҜпјҲеҰӮдёӢеӣҫпјүпјҢиҝҷиҝҮзЁӢдјҡиҠұжҜ”иҫғй•ҝзҡ„ж—¶й—ҙпјҢеӣ дёәе®ғиҰҒеҲҶжһҗиҜӯеҸҘзҡ„иҜӯжі•дёҺиҜӯд№үгҖӮ然еҗҺиҺ·еҫ—жңҖдјҳеҢ–еҗҺзҡ„жү§иЎҢи®ЎеҲ’пјҲsql planпјүпјҢ并еңЁеҶ…еӯҳдёӯеҲҶй…ҚдёҖе®ҡзҡ„з©әй—ҙдҝқеӯҳиҜҘиҜӯеҸҘдёҺеҜ№еә”зҡ„жү§иЎҢи®ЎеҲ’зӯүдҝЎжҒҜгҖӮ
В
гҖҖгҖҖ2гҖҒеҪ“з”ЁжҲ·з¬¬дәҢж¬ЎиҜ·жұӮжҲ–еӨҡж¬ЎиҜ·жұӮж—¶пјҢOracleдјҡиҮӘеҠЁжүҫеҲ°е…ҲеүҚзҡ„иҜӯеҸҘдёҺжү§иЎҢи®ЎеҲ’пјҢиҖҢдёҚдјҡиҝӣиЎҢHard parse,иҖҢжҳҜзӣҙжҺҘиҝӣиЎҢSoft parseпјҲжҠҠиҜӯеҸҘеҜ№еә”зҡ„жү§иЎҢи®ЎеҲ’и°ғеҮәпјҢ然еҗҺжү§иЎҢпјү,д»ҺиҖҢеҮҸе°‘ж•°жҚ®еә“зҡ„еҲҶжһҗж—¶й—ҙгҖӮ
В
гҖҖгҖҖжіЁж„Ҹзҡ„жҳҜпјҡOracleдёӯеҸӘиғҪе®Ңе…ЁзӣёеҗҢзҡ„иҜӯеҸҘпјҢеҢ…еӨ§е°ҸеҶҷгҖҒз©әж јгҖҒжҚўиЎҢйғҪиҰҒжұӮдёҖж ·ж—¶пјҢжүҚдјҡйҮҚеӨҚдҪҝз”Ёд»ҘеүҚзҡ„еҲҶжһҗз»“жһңдёҺжү§иЎҢи®ЎеҲ’гҖӮ
В
гҖҖгҖҖеҲҶжһҗиҝҮзЁӢеҰӮдёӢеӣҫпјҡ
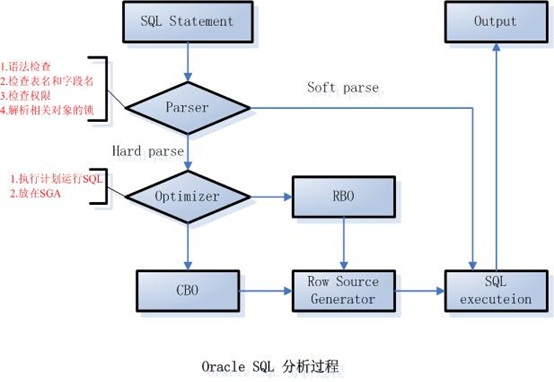
В еҜ№дәҺеӨ§йҮҸзҡ„гҖҒйў‘з№Ғи®ҝй—®зҡ„SQLиҜӯеҸҘпјҢеҰӮжһңдёҚйҮҮз”ЁBind еҸҳйҮҸзҡ„ж–№ејҸпјҢе“ӘOracleдјҡиҠұиҙ№еӨ§йҮҸзҡ„Shared latchдёҺCPUеңЁеҒҡHard parseеӨ„зҗҶпјҢжүҖд»ҘпјҢиҰҒе°ҪйҮҸжҸҗй«ҳиҜӯеҸҘзҡ„йҮҚз”ЁзҺҮпјҢеҮҸе°‘иҜӯеҸҘзҡ„еҲҶжһҗж—¶й—ҙпјҢйҖҡиҝҮдәҶи§ЈOracle SQLиҜӯеҸҘзҡ„еҲҶжһҗиҝҮзЁӢеҸҜд»ҘжҳҺзҷҪOracleзҡ„еҶ…йғЁеӨ„зҗҶйҖ»иҫ‘пјҢ并еңЁи®ҫи®ЎдёҺе®һзҺ°дёҠйҒҝе…ҚгҖӮ
В
еңЁз”ЁJDBCжҲ–е…¶е®ғжҢҒд№…еҢ–ж•°жҚ®(еҰӮHibernate,JDOзӯү)ж“ҚдҪңж—¶пјҢе°ҪйҮҸз”ЁеҚ дҪҚз¬ҰпјҲпјҹпјү
В
ORACLE sql зҡ„еӨ„зҗҶиҝҮзЁӢеӨ§иҮҙеҰӮдёӢпјҡ
В 1.иҝҗз”ЁHASHз®—жі•пјҢеҫ—еҲ°дёҖдёӘHASHеҖјпјҢиҝҷдёӘеҖјеҸҜд»ҘйҖҡиҝҮV$SQLAREA.HASH_VALUE жҹҘзңӢ
В 2.еҲ°shared pool дёӯзҡ„ library cache дёӯжҹҘжүҫжҳҜеҗҰжңүзӣёеҗҢзҡ„HASHеҖјпјҢеҰӮжһңеӯҳеңЁпјҢеҲҷж— йңҖзЎ¬и§ЈжһҗпјҢиҝӣиЎҢиҪҜи§Јжһҗ
В 3.еҰӮжһңshared poolдёҚеӯҳеңЁжӯӨHASHеҖјпјҢеҲҷиҝӣиЎҢиҜӯжі•жЈҖжҹҘпјҢжҹҘзңӢжҳҜеҗҰжңүиҜӯжі•й”ҷиҜҜ
В 4.еҰӮжһңжІЎжңүиҜӯжі•й”ҷиҜҜпјҢе°ұиҝӣиЎҢиҜӯд№үжЈҖжҹҘпјҢжЈҖжҹҘиҜҘSQLеј•з”Ёзҡ„еҜ№иұЎжҳҜеҗҰеӯҳеңЁпјҢиҜҘз”ЁжҲ·жҳҜеҗҰе…·жңүи®ҝй—®иҜҘеҜ№иұЎзҡ„жқғйҷҗ
В 5.еҰӮжһңжІЎжңүиҜӯд№үй”ҷиҜҜпјҢеҜ№иҜҘSQLиҝӣиЎҢи§ЈжһҗпјҢз”ҹжҲҗи§Јжһҗж ‘пјҢжү§иЎҢи®ЎеҲ’
В 6.з”ҹжҲҗORACLEиғҪиҝҗиЎҢзҡ„дәҢиҝӣеҲ¶д»Јз ҒпјҢиҝҗиЎҢиҜҘд»Јз Ғ并且иҝ”еӣһз»“жһңз»ҷз”ЁжҲ·
зЎ¬и§Јжһҗе’ҢиҪҜи§ЈжһҗйғҪеңЁз¬¬5жӯҘиҝӣиЎҢ
зЎ¬и§ЈжһҗйҖҡеёёжҳҜжҳӮиҙөзҡ„ж“ҚдҪңпјҢеӨ§зәҰеҚ ж•ҙдёӘSQLжү§иЎҢзҡ„70%е·ҰеҸізҡ„ж—¶й—ҙпјҢзЎ¬и§Јжһҗдјҡз”ҹжҲҗжү§иЎҢж ‘пјҢжү§иЎҢи®ЎеҲ’пјҢзӯүзӯүгҖӮ
еҪ“еҶҚж¬Ўжү§иЎҢеҗҢдёҖжқЎSQLиҜӯеҸҘзҡ„ж—¶еҖҷпјҢз”ұдәҺеҸ‘зҺ°library cacheдёӯжңүзӣёеҗҢзҡ„HASHеҖјпјҢиҝҷдёӘж—¶еҖҷдёҚдјҡзЎ¬и§ЈжһҗпјҢиҖҢдјҡиҪҜи§ЈжһҗпјҢ
йӮЈд№ҲиҪҜи§Јжһҗ究з«ҹжҳҜе№ІдәҶд»Җд№Ҳе‘ў?е…¶е®һиҪҜи§Јжһҗе°ұжҳҜи·іиҝҮдәҶз”ҹжҲҗи§Јжһҗж ‘пјҢз”ҹжҲҗжү§иЎҢи®ЎеҲ’иҝҷдёӘиҖ—ж—¶еҸҲиҖ—CPUзҡ„ж“ҚдҪңпјҢзӣҙжҺҘеҲ©з”Ёз”ҹжҲҗзҡ„жү§иЎҢи®ЎеҲ’иҝҗиЎҢ
иҜҘSQLиҜӯеҸҘгҖӮ
дёӢйқўж‘ҳжҠ„eygleж·ұе…Ҙи§ЈжһҗORACLE дёӯе…ідәҺSQLжү§иЎҢиҝҮзЁӢзҡ„жҸҸиҝ°
В 1.йҰ–е…ҲиҺ·еҫ—library cache latch,ж №жҚ®SQLзҡ„HASH_VALUEеңЁlibrary cacheдёӯжҹҘжүҫжҳҜеҗҰеӯҳеңЁжӯӨHASH_VALUEпјҢеҰӮжһңжүҫеҲ°иҝҷдёӘHASH_VALUEпјҢз§°д№ӢдёәиҪҜи§ЈжһҗпјҢServerиҺ·еҫ—ж”№SQLжү§иЎҢи®ЎеҲ’иҪ¬еҗ‘第4жӯҘпјҢеҰӮжһңжүҫдёҚеҲ°е…ұдә«д»Јз Ғе°ұиҝӣиЎҢзЎ¬и§ЈжһҗгҖӮ
В 2.йҮҠж”ҫlibrary pool cache,иҺ·еҫ—shared pool latch,жҹҘжүҫ并й”Ғе®ҡиҮӘз”ұз©әй—ҙ(еңЁbucket дёӯжҹҘжүҫchunk)гҖӮеҰӮжһңжүҫдёҚеҲ°пјҢжҠҘORA-04031й”ҷиҜҜгҖӮ
В 3.йҮҠж”ҫshared pool latch,йҮҚж–°иҺ·еҫ—library cache latch,е°ҶSQLжү§иЎҢи®ЎеҲ’ж”ҫе…Ҙlibrary cacheдёӯгҖӮ
В 4.йҮҠж”ҫlibrary cache latch,дҝқжҢҒnullжЁЎејҸзҡ„library cache pin/lockгҖӮ
В 5.ејҖе§Ӣжү§иЎҢгҖӮ
Library cache latchеҸҜд»ҘзҗҶи§ЈдёәзЎ¬/иҪҜи§Јжһҗзҡ„ж—¶еҖҷеҸ‘з”ҹзҡ„пјҢеӣ дёәи§Јжһҗзҡ„ж—¶еҖҷдјҡжҗңзҙўlibrary cacheпјҢжүҖд»Ҙдјҡдә§з”ҹlibrary cache latch
Library cache pin жҳҜеңЁжү§иЎҢзҡ„йҳ¶ж®өеҸ‘з”ҹзҡ„гҖӮ



зӣёе…іжҺЁиҚҗ
е…ідәҺSQLиҜӯеҸҘеңЁиҝӣе…Ҙoracleеә“зј“еӯҳд№ӢеҗҺзҡ„жү§иЎҢйЎәеәҸзҡ„з®Җжһҗ~пјҒ
Oracle sqlжү§иЎҢжөҒзЁӢеӣҫ_SQLжү§иЎҢиҝҮзЁӢдёҖгҖҒsqlиҜӯеҸҘзҡ„жү§иЎҢжӯҘйӘӨпјҡ1пјүиҜӯжі•еҲҶжһҗпјҢеҲҶжһҗиҜӯеҸҘзҡ„иҜӯжі•жҳҜеҗҰз¬ҰеҗҲ规иҢғпјҢиЎЎйҮҸиҜӯеҸҘдёӯеҗ„иЎЁиҫҫејҸзҡ„ж„Ҹд№үгҖӮ2пјү иҜӯд№үеҲҶжһҗпјҢжЈҖжҹҘиҜӯеҸҘдёӯж¶үеҸҠзҡ„жүҖжңүж•°жҚ®еә“еҜ№иұЎжҳҜеҗҰеӯҳеңЁпјҢдё”з”ЁжҲ·жңүзӣёеә”зҡ„жқғйҷҗгҖӮ3пјү...
еҫҲйҖӮеҗҲејҖеҸ‘дәәе‘ҳеңЁзј–еҶҷSQLж—¶жіЁж„ҸпјҢиҝҷйҮҢиҷҪ然иҜҙжҳҜOracleзҡ„дјҳеҢ–пјҢе…¶е®һпјҢеҫҲеӨҡжҳҜж ҮеҮҶSQLйңҖиҰҒжіЁж„Ҹзҡ„еҶҷжі•гҖӮе…·жңүйқһеёёй«ҳзҡ„е…ұйҖҡжҖ§гҖӮ 1.йҖүз”ЁйҖӮеҗҲзҡ„ORACLEдјҳеҢ–еҷЁ 2.HEREеӯҗеҸҘдёӯзҡ„иҝһжҺҘйЎәеәҸ 3.йҖҡиҝҮеҶ…йғЁеҮҪж•°жҸҗй«ҳSQLж•ҲзҺҮ 4.EXISTSдёҺIN...
еңЁеӣһзӯ”иҝҷдёӘй—®йўҳеүҚпјҢжҲ‘们е…ҲжқҘеӣһйЎҫдёҖдёӢпјҡеңЁORACLEж•°жҚ®еә“жһ¶жһ„дёӢпјҢSQLиҜӯеҸҘз”ұз”ЁжҲ·иҝӣзЁӢдә§з”ҹпјҢ然еҗҺдј еҲ°зӣёеҜ№еә”зҡ„жңҚеҠЎз«ҜиҝӣзЁӢпјҢд№ӢеҗҺз”ұжңҚеҠЎеҷЁиҝӣзЁӢжү§иЎҢиҜҘSQLиҜӯеҸҘпјҢеҰӮжһңжҳҜSELECTиҜӯеҸҘпјҢжңҚеҠЎеҷЁиҝӣзЁӢиҝҳйңҖиҰҒе°Ҷжү§иЎҢз»“жһңеӣһдј з»ҷз”ЁжҲ·иҝӣзЁӢгҖӮ...
гҖҖOracleеңЁеҶ…йғЁжү§иЎҢдәҶи®ёеӨҡе·ҘдҪң: и§ЈжһҗSQLиҜӯеҸҘ, дј°з®—зҙўеј•зҡ„еҲ©з”ЁзҺҮ, з»‘е®ҡеҸҳйҮҸ , иҜ»ж•°жҚ®еқ—зӯүгҖӮ гҖҖпјҲ5пјүеңЁSQL*Plus , SQL*Formsе’ҢPro*CдёӯйҮҚж–°й…ҚзҪ®ARRAYSIZEеҸӮж•°, иғҪеӨҹеўһеҠ жҜҸж¬Ўж•°жҚ®еә“и®ҝй—®зҡ„жЈҖзҙўж•°жҚ®йҮҸ ,е»әи®®еҖјдёә200гҖӮ гҖҖ...
ORACLEзҡ„и§ЈжһҗеҷЁжҢүз…§д»ҺеҸіеҲ°е·Ұзҡ„йЎәеәҸеӨ„зҗҶFROMеӯҗеҸҘдёӯзҡ„иЎЁеҗҚпјҢFROMеӯҗеҸҘдёӯеҶҷеңЁжңҖеҗҺзҡ„иЎЁ(еҹәзЎҖиЎЁ driving table)е°Ҷиў«жңҖе…ҲеӨ„зҗҶпјҢеңЁFROMеӯҗеҸҘдёӯеҢ…еҗ«еӨҡдёӘиЎЁзҡ„жғ…еҶөдёӢ,дҪ еҝ…йЎ»йҖүжӢ©и®°еҪ•жқЎж•°жңҖе°‘зҡ„иЎЁдҪңдёәеҹәзЎҖиЎЁгҖӮеҰӮжһңжңү3дёӘд»ҘдёҠзҡ„иЎЁ...
SQLиҜӯеҸҘдјҳеҢ–иҝҮзЁӢдјҳеҢ–зӯ–з•Ҙ 21. /*+ORDERED*/ ж №жҚ®иЎЁеҮәзҺ°еңЁFROMдёӯзҡ„йЎәеәҸ,ORDEREDдҪҝORACLEдҫқжӯӨйЎәеәҸеҜ№е…¶иҝһжҺҘ. дҫӢеҰӮ: SELECT /*+ORDERED*/ A.COL1,B.COL2,C.COL3 FROM TABLE1 A,TABLE2 B,TABLE3 C WHERE A.COL1=B.COL1...
гҖҖе…ідәҺOracleпјҢжҲ‘们йғҪе·Із»ҸеӯҰд№ дәҶSQLиҜӯеҸҘпјҢйӮЈд№ҲOracleе…¶е®һе·Із»ҸеӯҰд№ дәҶдёҖеӨ§еҚҠпјҢжҺҘдёӢжқҘиҮӘе·ұеӯҰд№ Oracleдё»иҰҒжҳҜзңӢдёҖдёӢд»–зҡ„жҰӮеҝөпјҢOracleе’ҢSQL ServerиҝҳжҳҜжңүеҫҲеӨ§дёҚеҗҢзҡ„пјҢзҶҹжӮүд»–зҡ„иЎЁз©әй—ҙиҝҷдәӣжҰӮеҝөпјҢдәҶи§Јд»–зҡ„еӣҫеҪўз•ҢйқўпјҢе’ҢеӨҮд»Ҫ...
жү§иЎҢи®ЎеҲ’иЎЁзӨәдәҶSQLиҜӯеҸҘжү§иЎҢйЎәеәҸдёҺж–№жі•гҖӮ жү§иЎҢи®ЎеҲ’зҡ„еӯҳеӮЁж–№ејҸпјҡ дёҖдҪҶдә§з”ҹжү§иЎҢи®ЎеҲ’гҖӮиҝҷдёӘи®ЎеҲ’е°ұдјҡе’ҢsqlиҜӯеҸҘдёҖиө·еӯҳеӮЁеңЁlibrary cacheдёӯгҖӮsqlиҜӯеҸҘжҢүз…§hashзҡ„з®—жі•пјҢдә§з”ҹhash еҖјпјҢиҝҷйҮҢпјҢжҲ‘们еҸҜд»ҘжҠҠhashеҖјеҪ“еҒҡдёҖдёӘPKеҖјпјҢ...
ж¶ҲиҖ—еңЁеҮҶеӨҮж–°зҡ„SQLиҜӯеҸҘзҡ„ж—¶й—ҙжҳҜOracle SQLиҜӯеҸҘжү§иЎҢж—¶й—ҙзҡ„жңҖйҮҚиҰҒзҡ„з»„жҲҗйғЁеҲҶгҖӮдҪҶжҳҜйҖҡиҝҮзҗҶи§ЈOracleеҶ…йғЁдә§з”ҹжү§иЎҢи®ЎеҲ’зҡ„жңәеҲ¶пјҢиғҪеӨҹжҺ§еҲ¶OracleиҠұиҙ№еңЁиҜ„дј°иҝһжҺҘйЎәеәҸзҡ„ж—¶й—ҙж•°йҮҸпјҢ并且иғҪеңЁеӨ§дҪ“дёҠжҸҗй«ҳжҹҘиҜўжҖ§иғҪгҖӮ
жү§иЎҢи®ЎеҲ’зҡ„жҜҸдёҖжӯҘиҝ”еӣһдёҖз»„иЎҢпјҢе®ғ们жҲ–иҖ…дёәдёӢдёҖжӯҘжүҖдҪҝз”ЁпјҢжҲ–иҖ…еңЁжңҖеҗҺдёҖжӯҘж—¶иҝ”еӣһз»ҷеҸ‘еҮәSQLиҜӯеҸҘзҡ„з”ЁжҲ·жҲ–еә”з”ЁгҖӮз”ұжҜҸдёҖжӯҘиҝ”еӣһзҡ„дёҖз»„иЎҢеҸ«еҒҡиЎҢжәҗ(row sourceпјүгҖӮеӣҫ5-1ж ‘зҠ¶еӣҫжҳҫзӨәдәҶд»ҺдёҖжӯҘеҲ°еҸҰдёҖжӯҘиЎҢж•°жҚ®зҡ„жөҒеҠЁжғ…еҶөгҖӮжҜҸжӯҘзҡ„...
Oracleж•°жҚ®еә“еҶ…йғЁзҡ„ж•°жҚ®ж“ҚдҪңеҸҜд»ҘйҖҡиҝҮsqlиҜӯеҸҘжү§иЎҢеӨ„зҗҶпјҢsqlдёҺCгҖҒBasicзӯүиҜӯиЁҖдёҚйҖҡпјҢж•°жҚ®зҡ„и®ҝй—®ж–№жі•е’Ңж“ҚдҪңйЎәеәҸдёҚз”ЁжӯЈзЎ®жҢҮе®ҡпјҢжҳҜиҰҒе‘ҠиҜүж•°жҚ®еә“еј•ж“ҺиҰҒеҒҡд»Җд№Ҳе°ұеҸҜд»ҘдәҶгҖӮOracleдёҚд»…еҸҜд»ҘйҖҡиҝҮеҹәжң¬зҡ„sqlиҝӣиЎҢз®ҖеҚ•зҡ„ж•°жҚ®ж“ҚдҪңпјҢиҝҳ...
еңЁиҪ¬з§»ж•°жҚ®еә“пјҢиҝӣиЎҢж•°жҚ®еҜје…Ҙзҡ„ж—¶еҖҷпјҢйҒҮеҲ°дёҖ件йә»зғҰдәӢпјҢе°ұжҳҜиЎЁй—ҙеӨ–й”®зәҰжқҹзҡ„еӯҳеңЁпјҢеҜјиҮҙinsertйў‘йў‘жҠҘй”ҷпјҢжү№йҮҸжү§иЎҢsqlиҜӯеҸҘеҸҲжҳҜйЎәеәҸжү§иЎҢпјҢжІЎеҠһжі•жҲ‘еҸӘеҘҪжүӢеҠЁиҫ“е…ҘгҖӮ 然еҗҺиҫ“е…ҘеҲ°дёҖеҚҠзҒөе…үдёҖй—ӘпјҢдёәд»Җд№ҲдёҚе…ҲжҠҠеӨ–й”®зәҰжқҹе…ЁйғЁзҰҒз”Ёе…Ҳ...
SQL SelectиҜӯеҸҘе®Ңж•ҙзҡ„жү§иЎҢйЎәеәҸпјҡ1гҖҒfromеӯҗеҸҘз»„иЈ…жқҘиҮӘдёҚеҗҢж•°жҚ®жәҗзҡ„ж•°жҚ®пјӣ2гҖҒwhereеӯҗеҸҘеҹәдәҺжҢҮе®ҡзҡ„жқЎд»¶еҜ№и®°еҪ•иЎҢиҝӣиЎҢзӯӣйҖүпјӣ3гҖҒgroup byеӯҗеҸҘе°Ҷж•°жҚ®еҲ’еҲҶдёәеӨҡдёӘеҲҶз»„пјӣ4гҖҒдҪҝз”ЁиҒҡйӣҶеҮҪж•°иҝӣиЎҢи®Ўз®—пјӣ5гҖҒдҪҝз”ЁhavingеӯҗеҸҘзӯӣйҖүеҲҶз»„пјӣ...
10гҖҒиҜҙжҳҺпјҡеҮ дёӘз®ҖеҚ•зҡ„еҹәжң¬зҡ„sqlиҜӯеҸҘ йҖүжӢ©пјҡselect * from table1 where иҢғеӣҙ жҸ’е…Ҙпјҡinsert into table1(field1,field2) values(value1,value2) еҲ йҷӨпјҡdelete from table1 where иҢғеӣҙ жӣҙж–°пјҡupdate table1 set field1...
6.2.4 ж ҮиҜҶSQLиҜӯеҸҘд»Ҙдҫҝд»ҘеҗҺеҸ–еӣһи®ЎеҲ’ 153 6.2.5 ж·ұе…ҘзҗҶи§ЈDBMS_XPLANзҡ„з»ҶиҠӮ 156 6.2.6 дҪҝз”Ёи®ЎеҲ’дҝЎжҒҜжқҘи§ЈеҶій—®йўҳ 161 6.3 е°Ҹз»“ 169 第7з« й«ҳзә§еҲҶз»„ 170 7.1 еҹәжң¬зҡ„GROUP BYз”Ёжі• 171 7.2 HAVINGеӯҗеҸҘ 174 7.3 GROUP...
1.йҖүз”ЁйҖӮеҗҲзҡ„ORACLEдјҳеҢ–еҷЁгҖӮ...3. е…ұдә«SQLиҜӯеҸҘгҖӮ 4. йҖүжӢ©жңҖжңүж•ҲзҺҮзҡ„иЎЁеҗҚйЎәеәҸ(еҸӘеңЁеҹәдәҺ规еҲҷзҡ„дјҳеҢ–еҷЁдёӯжңүж•Ҳ)гҖӮ5. WHEREеӯҗеҸҘдёӯзҡ„иҝһжҺҘйЎәеәҸгҖӮ6.SELECTеӯҗеҸҘдёӯйҒҝе…ҚдҪҝз”Ё вҖҳ * вҖҳ ...пјҲеҶ…йғЁж¶өзӣ–дәҶйқһеёёеӨҡзҡ„дјҳеҢ–规еҲҷпјү
дёәдәҶдёҚйҮҚеӨҚи§ЈжһҗзӣёеҗҢзҡ„SQLиҜӯеҸҘ,еңЁз¬¬дёҖж¬Ўи§Јжһҗд№ӢеҗҺ, ORACLEе°ҶSQLиҜӯеҸҘеӯҳж”ҫеңЁеҶ…еӯҳдёӯ.иҝҷеқ—дҪҚдәҺзі»з»ҹе…ЁеұҖеҢәеҹҹSGA(system global area)зҡ„е…ұдә«жұ (shared buffer pool)дёӯзҡ„еҶ…еӯҳеҸҜд»Ҙиў«жүҖжңүзҡ„ж•°жҚ®еә“з”ЁжҲ·е…ұдә«. еӣ жӯӨ,еҪ“дҪ жү§иЎҢдёҖдёӘ...
(1) йҖүжӢ©жңҖжңүж•ҲзҺҮзҡ„иЎЁеҗҚйЎәеәҸ(еҸӘеңЁеҹәдәҺ规еҲҷзҡ„дјҳеҢ–еҷЁдёӯжңүж•Ҳ) (2) WHEREеӯҗеҸҘдёӯзҡ„иҝһжҺҘйЎәеәҸ.пјҡ (3) SELECTеӯҗеҸҘдёӯйҒҝе…ҚдҪҝз”Ё вҖҳ * вҖҳ ........